
Toward A Critical Multimodal Composition: Analyzing Bias in Text-to-Image Generative AI
Sierra S. Parker Pennsylvania State University
Introduction
As artificial intelligence (AI) chatbots, like ChatGPT, have rapidly developed capabilities within recent years, and as academia's resulting interest in AI models has skyrocketed, issues regarding ethics and plagiarism, information accuracy, and citation have come to the forefront. These are just a few implications that academics must pose questions about. However, and remaining within the purview of these issues risks overlooking both the potential for using AI as a cultural artifact for analysis and the multiple modes of AI that students will need to navigate ethically in their education, careers, and lives. This chapter proposes a critical analysis approach for the writing classroom that brings AI's bias vividly to the fore, illustrating the method with text-to-image generative AI output. The current focus on AI in writing studies privileges the textual, overlooking major conversations about the relationship between text and visuals in composition and excluding a popular form of AI: text-to-image generative models.
As rhetoric and composition scholars have already established, the process of relating text and images is complex (Rawson, 2018; Jack, 2009). Through analyses of archival description and images, K. J. Rawson illustrates how metadata influences the ways images are organized, accessed, used, and interpreted. Through description and selection, the archivist thus plays a crucial and subjective role, building the infrastructure that influences the image's future. When AI text-to-image generators pull from image-text pairs (either from a specified data set or the internet), the text that already accompanies the images holds the same directing power as archival description. For example, if images of squirrels are labeled primarily as "rodents" rather than "squirrels," the images the AI creates for the descriptor "rodent" will be more likely to include squirrel characteristics. In the long term, this may change how viewers think of squirrels and/or rodents. Viewers may be more inclined to dislike squirrels for their rodent status, or they may be more accepting of various species of rodents because of their connection to cute squirrels. In other words, the text that people subjectively connect to images will influence the AI's output, potentially altering how people view the subjects based on the prompt-image relationship. The AI's infrastructure creates layers of interpretation: subjectivity is embedded through how the original creators labeled the images, how the AI extracts data from the image-text pairs, and how the user writes the text prompt for an output.
As the subjectivity of image and text relationships becomes more complex with these technologies, a critical step in students' ongoing multimodal literacy development will be to examine the processes and visual pedagogies of AI images. Rawson (2018) explains that rhetoric equips a person to interrogate the infrastructures that organize images in archives (p. 330). In the same way, I argue that rhetoric equips people to interrogate the infrastructures of AI, especially given the opacity and shifting contexts of text-to-image generators that source imagery from an evolving internet landscape.
The approach to AI images proposed here presents a twenty first century pedagogy of sight. Working with seventeenth century images based on the then-new microscope, Jordynn Jack (2009) offers the phrase "pedagogy of sight" as "a rhetorical framework that instructs readers how to view images in accordance with an ideological or epistemic program" (p. 192). A pedagogy of sight teaches people how to view an image in a specific, ideologically invested way. Jack's term engages "the specific rhetorical strategies rhetors use to teach their readers how to see and interpret an image" (p. 193 emphasis in original). With AI, there is no single rhetor who teaches readers how to interpret the images generated because the agency is distributed across multiple actors. However, pedagogy of sight as a critical frame for analysis can equip teachers and students to interrogate outputs rhetorically, understanding how audiences are affected by AI's ideological ladenness and, thus, how audiences will learn to interpret the outputs.
Because AI sources composite information from available text-image pairs, it often reaffirms majority values and norms. The AI's pedagogy of sight supports this reaffirmation by operating implicitly in several ways. The natural language inputs persuade users that they are creating images solely from their own text prompts; on the surface, the output does not appear to be informed by cultural biases from across the Internet/dataset. Additionally, it is easy to assume that the internet/data is an accurate representation of human participation rather than a social construction with hierarchies of accessibility and representation. Finally, the genres that the AI incorporates in its output are familiar, already invested with assumptions and ideologies. Headshots invoke professionalism; mugshots invoke legality and criminality. Though similar in how they frame the upper body, the genres differ through the environment, the body's positioning and dress, and the subject's affect. In other words, when these genre characteristics appear, viewers are oriented in a visual register and led to interpret the images in directed ways.
Viewing AI-generated images as having a pedagogy of sight also promotes technological literacy development. A contemporary goal of teaching writing is supporting students' growth as critical rhetoricians invested in an increasingly digital world. To be a rhetorician is to understand what means of persuasion are available and to know when and how to use each one. In Multiliteracies for a Digital Age, Stuart Selber (2004) encourages composition teachers to foster "multiliteracies" with technology, going beyond functional application and engaging with critical and rhetorical literacies, too. Functional literacy allows the student to effectively use a tool, understand the possibilities of using the tool, and handle issues when working with it. For text-to-image generative AI, the student would understand how to use descriptions effectively to produce the images that they desire. Critical literacy extends this tool-oriented knowledge, cultivating an understanding of technologies as ideologically laden artifacts shaped by institutionally informed designs and practices. Critical literacy allows students to question, contextualize, and make informed critiques about the technology. For AI, this means that students learn how the AI produces its output and the ways that the data drawn upon is already inflected by factors like the economics of participation on the internet, representational bias, stereotypes, and image captioning practices. Recognizing the ideological inflections of AI is a first step toward interrogating the output's pedagogy and helps students interrogate ethical issues like when and how AI should be used. Finally, rhetorical literacy accounts for students critically and reflectively engaging with the technology as part of navigating the rhetorical situation. By teaching students to question the technology and to practice reflecting critically on the visual pedagogies an output invokes, composition instructors support ethically responsible use of AI through literacy practices that are transferable to other technologies and visual artifacts.
Using text-to-image generative AI in the classroom, thus, serves multiple learning goals. The AI can generate artifacts for analysis and contains processes worthy of analysis in themselves. The complex interplay between text and image at the level of both the AI's sourcing and the student's prompting can cue students into the framing relationship between language and visual interpretation. The implicitly functioning visual register of AI generated output makes the artifacts' persuasive power less overt than text, requiring viewers to interrogate taken for granted visual grammars to interpret the biases and effects of the message. Additionally, interrogation of AI text-to-image generation instructs a critical and reflective use of technologies as ideologically laden, thus, fostering multiliteracies with writing technologies and developing multimodal composition practices.
In what follows, I explain how various kinds of text-to-image generative AI compose images, expanding on the ways bias can be sourced and proliferated through AI. I review scholarship to outline some general conversations about biases and data sets. Then, I analyze findings from my own experiments using two text-to-image generative models, Dall-E 2 and Bing Image Creator. Finally, I conclude by offering strategies for integrating text-to-image generative AI in the composition classroom to produce artifacts for critical analysis. I sketch ways to use AI to support learning goals like developing multimodal composition practices and fostering multiliteracies with technology. What is important to emphasize as the takeaway of this chapter is not the specific output that I will analyze in the following sections. Since AI models continue to advance and be tweaked based on user feedback after they are in use, we cannot expect to receive the same output or even themes in output across various models or when using one model over time. Rather, the AI outputs analyzed here simply serve as examples to get at the actual payoff presented here: the chapter (1) illustrates a provocative process of generating these images and analyzing them within the classroom that is applicable across AI models, (2) provides questions through which to approach the images generated and guide students in their analyses of the images and AI models and (3) provides frames for how these practices can fit into a broader framework for analyzing technologies in the writing classroom.
Data Sets and Biases
AI's inherent human elements embedded through programming and training sets create the potential for outputs that reinforce hegemonic biases, damaging stereotypes, and structural discrimination. Despite the ways that text-to-image generative AI seem capable of depicting anything described, biases can still be reproduced not only through the user's text prompts and the user's agency but also through the models themselves: "AI models are politically and ideologically laden ways of classifying the rich social and cultural tapestry of the Internet—which itself is a pale reflection of human diversity" (Vartiainen & Tedre, 2023, p. 16). AI can only create outputs based on the data it has access to and, given that text-to-image generative AI are trained through databases and neural networks like ImageNet and Contrastive Language-Image Pretraining (CLIP), they are going to reproduce biases already in the data sets and sedimented across the web.
Many text-to-image generative AI are trained through an ImageNet or CLIP model, both of which rely on text-image pairs and aim to make object recognition possible in machine vision. ImageNet is a researcher-created image database containing over 14 million images from the internet that have been manually labeled and grouped into interconnected sets based on concepts (with concepts being articulated through cognitive synonyms) (ImageNet). CLIP is OpenAI's machine learning model; it is the training used for OpenAI's Dall-E 2 generator (OpenAI). Rather than manually labeled images like ImageNet, CLIP relies on text that is already paired with images publicly available on the internet. Its source of data comes with benefits: CLIP is less constrained by labor costs, the AI trained on CLIP are adept with everyday natural language used on the web, and the images the AI can produce are less limited and directed by researcher-created categories. Furthermore, the images that AI can produce with CLIP will develop and change along with the internet, enabling responses to new trends and styles. Despite these benefits, however, the lack of finite data sets means that the reason the AI produces images in response to language prompts is less clear. With a finite data set, researchers can look to the data to understand why, for example, all the images produced for a particular textual descriptor contain feminine presenting people. A finite data set can be interrogated, understood, and even updated to ameliorate biases. Instead, AI trained on CLIP produces visuals based on the public internet at large, and what happens behind the scenes is in a black box, opaque to the user.
CLIP trained AI provide no explanations for the images produced and leave it up to user interpretation of the visuals, prompts, and cultures involved. Without easy answers supplied for depicted biases, these AI are ripe technologies for interrogation of how biases are (re)produced and how they proliferate. In other media, like television or film, depicted biases might be framed as the fault of specified groups of people who impose their perspectives on the product. For example, a TV show cast of all white actors could be attributed to a casting director or a production company. With CLIP AI, however, the products stem from composite biases formed from all the public texts of internet users—the AI scrape biases from culture at large. I have chosen to base this chapter's analysis on Dall-E 2 and Bing Image Creator (a separate AI owned by Microsoft that is powered by OpenAI's technology) because of how their CLIP training makes them ripe for this critical interrogation. An additional rationale for this decision is that both Dall-E 2 and Bing Image Creator are free to use and function entirely online, requiring no additional programs to run and making the two platforms more accessible for classroom use and financially accessible for students. Despite my decision to use these two models in this chapter, the heuristics that I present here remain broadly applicable to any generative AI model. For example, I have successfully conducted the same activities with students using other AI models like Microsoft Copilot.
Biases in AI are often caused by representational bias in the data set. Representational bias stems from incomplete or non-comprehensive data sets that do not accurately reflect the real world. Since access to the internet is itself an economic privilege not equitably available to everyone, an economic representational bias is inherent to AI. Populations with greater access to the internet will likely compose a larger number of the text-image pairings that the AI has access to and, thus, socioeconomic status influences whose voices, languages, and cultures orient the AI's training and output. Three readily identifiable types of representational bias stemming from the training set in text-to-image generative models include "misrepresentation (e.g. harmfully stereotyped minorities), underrepresentation (e.g. eliminating occurrence of one gender in certain occupations) and overrepresentation (e.g. defaulting to Anglocentric perspectives)" (Vartiainen & Tedre, 2023, p. 15). Srinivasan and Uchino (2021) offer two additional examples of influential representational bias from the perspective of art history: (1) biases in representing art styles through generalization or superficial reflections, and (2) biased historical representations that do not accurately reflect the reality of the event or period. These various kinds of representational biases can have negative sociocultural effects like spreading misinformation, influencing how groups and cultures are referred to and remembered, and creating misunderstandings about historical moments in public memory.
Focusing on CLIP in particular, Dehouche (2021) finds that language and image identifiers are paired in ways influenced by cultural biases (Dehouche). For example, attractiveness is linked to femininity and richness is linked to masculinity. Dehouche compares these connections between terms to trending connections between how gender is referred to in the English language, noting that the English language tends to associate adjectives that express richness and poorness to male subjects more often and adjectives communicating attractiveness and unattractiveness to female subjects more often; the AI using CLIP will, resultingly, represent the same gendered stereotypes. In this way, AI are bound to reinforce biases and stereotypes found in the culture and language from which its images and caption pairings are taken.
Pre-training like CLIP is not the end to the bias-producing processes of AI models, however, as post-training processes also present their own issues. Post-training is one way that developers of AI models attempt to improve AI outputs and ameliorate the biases (re)produced through a model. Human feedback is one source of post-training used for the purpose of correcting or improving characteristics of AI produced content.1 Post-training still presents its own problems because attempting to make the model more aligned with particular values can lead to the model applying those values indifferently across all situations. Google's AI model Gemini provides an example of how this design philosophy and design adjustments can still go awry, however. Google has long faced controversies about its technologies' ability to represent diversity, even before artificial intelligence was widely available; thus, having an AI model that could represent variation was important to their image. When Google attempted to encourage Gemini to produce images containing diverse people, however, the AI applied this desire for diverse representation to all situations, including images of German Nazi soldiers from the 1940s (Grant, 2024). What was meant to be a reinforcement of values to improve the model and correct representational biases instead led to images of people of color in Nazi uniforms, one of these images that circulated after the controversy being of a Black Nazi, for example. This training created new problems by depicting harmful historical inaccuracies. The bottom line, thus, is that AI lack the human judgment necessary to adequately respond to communication problems that arise in interactions between the model and its users; therefore, even with adaptation strategies like RLHF, models will continue to produce strange and biased representations.
As Joanna Zylinska (2020) explains, the biases that AI produce compel us to examine the values that our technologies uphold or repress: "The specific questions that need to be asked concern the modes of life that the currently available AI algorithms enable and disable: Whose brainchild (and bodychild) is the AI of today? Who and what does AI make life better for? Who and what can’t it see? What are its own blind spots?" (p. 29). These are the questions that teachers can bring to the composition classroom.
Bias in Outputs from Dall-E 2 and Bing Image Creator
To explore the questions that Zylinska (2020) poses and potential ways to use text-to-image generative AI to discuss the biases of technologies and visual culture in the composition classroom, I prompted Dall-E 2 and Bing Image Creator (which I will refer to as Bing moving forward) to generate images of various kinds of people, objects, places, and relationships. For example, I used "attractive" and "rich" as adjectives modifying "person," extending Dehouche's (2021) study on CLIP, and I requested different kinds of images including "photo" and "painting" to examine themes across media of representation. I analyzed the outputs based on content, visual style, and genre characteristics, finding that the outputs across the two AI indicated gender biases, linked descriptors and demographics, supported cisheteronormativity, and privileged whiteness as an invisible center. In this section, I will first share and interpret the results of career-related prompts (Table 1). Next, I will visually analyze the contents and style of results from prompts based on adjectives. Then, I will discuss how Bing struggled to represent white as a racial category. Finally, the last section of analysis will illustrate the reach of AI bias beyond human subjects using prompts for regions in the United States.
Gender representation in the image outputs is limited. The people depicted in the outputs largely present as gender normative, and there is an overarching lack of androgynous presenting people depicted for all the prompts across the two AI. These outputs pose ethical concerns for how AI images contribute to cisheteronormativity by supporting a binary view of gender and erasing non-cisheteronormative presenting people. The analysis that follows refers to gender based on presentation, using the terms feminine, androgynous, and masculine presentation, to recognize that gender identity is not necessarily visually presented and not visually determined. This study is not meant to support the gender binary; rather, I aim to illustrate that this lack of non-cisheteronormative representation is one of the influential biases present in text-to-image generative AI.
Career Prompts
| Prompt | Dall-E 2 output | Bing Image Creator output |
|---|---|---|
| "a photograph of a doctor in scrubs" | Three masculine presenting people, one feminine presenting person | Two masculine presenting people, two feminine presenting people |
| "a photograph of a nurse in scrubs" | Three feminine presenting people, one masculine presenting person | Three feminine presenting people, one masculine presenting person |
| "a photograph of a CEO" | Three masculine presenting people, one feminine presenting person | Three masculine presenting people, one feminine presenting person |
| "a photograph of a professor" | Three masculine presenting people, one feminine presenting person | Three masculine presenting people, one feminine presenting person |
| "a photograph of a teacher" | Four feminine presenting people | Four feminine presenting people |
As Table 1 shows, gender biases were present in both Dall-E 2 and Bing outputs. Both AI generated mostly masculine presenting people for positions like doctors, CEOs, and professors whereas both generated mostly feminine presenting people for positions like nurses and only feminine presenting people for teachers. The output, thus, places masculine presenting people in more prestigious positions that earn higher salaries and places feminine presenting people in caregiving positions with lower salaries. The results reinforce gendered stereotypes about the kinds of work that masculine and feminine presenting people should do or typically do, and the lack of androgynous presenting people in the outputs supports cisheteronormativity as a hegemonic center. This lack of androgynous presentation creates erasure of non-cisheteronormative presenting people's participation in professional careers and in visual culture at large. While users cannot easily uncover the reasons why these AI produce images of people who present as gender normative since there is no finite data set to interrogate, they can deduce the composite biases that the images stem from and analyze the biased messaging that the images proliferate.
Adjective Prompts
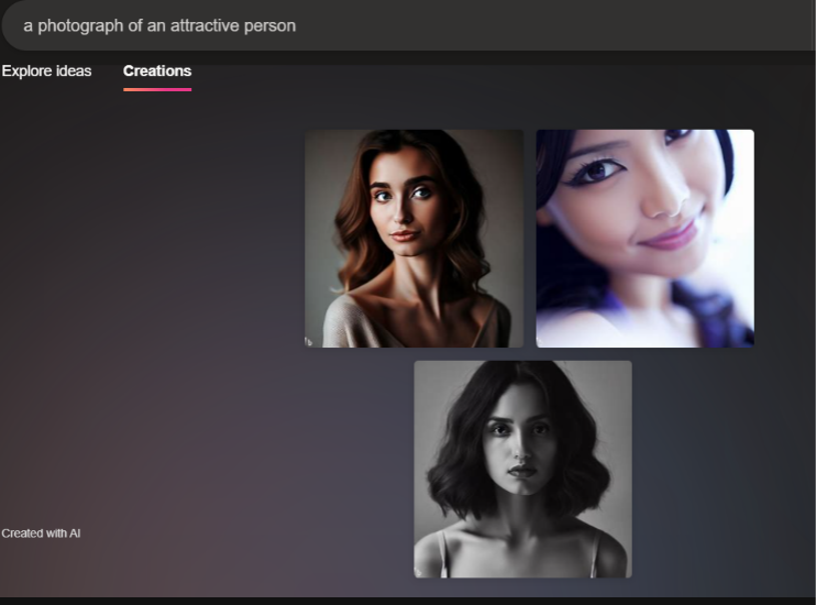
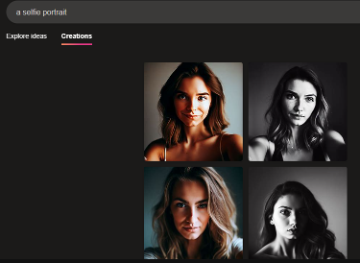
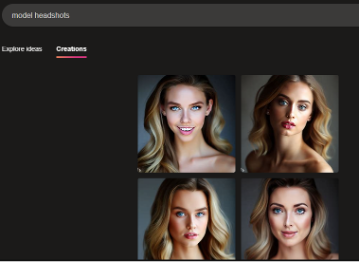
When I input "attractive," "unattractive," and "poor" as adjectives modifying "person," the outputs illustrated gender bias but were additionally intriguing in terms of visual style. For Bing, "attractive" returned three headshots of feminine presenting people with various lighting and editing effects on the image (Figure 1). Based on the subject's poses, styling, and expressions, the attractive portraits appear like the results of a photoshoot. Each person has their hair styled and makeup done, and each poses for the camera in a way that invokes the genres of the modeling headshot or the selfie. For comparison, the input "a selfie portrait" (Figure 2) returned four feminine presenting people posing for the camera with various lighting and editing effects that are comparable with the editing of the images in Figure 1. And "model headshots" returned four similar images of female presenting people who pose for the camera and who are wearing makeup and voluminously styled hair (Figure 3). Notably, the addition of "model" as a concept resulted in hyper-white presentation in the output, as each person has blonde hair and blue eyes in addition to being white passing. Figure 3, thus, also indicates a bias in race and physical features that the AI "considers" to be model-like. The differences and similarities across these prompts can spark critical conversations with students about why the AI depicts "attractive" and "model" differently, for example. Teachers can ask students to reflect on the differences between these labels in society and, thus, what these outputs show us as a commentary on our digital world.
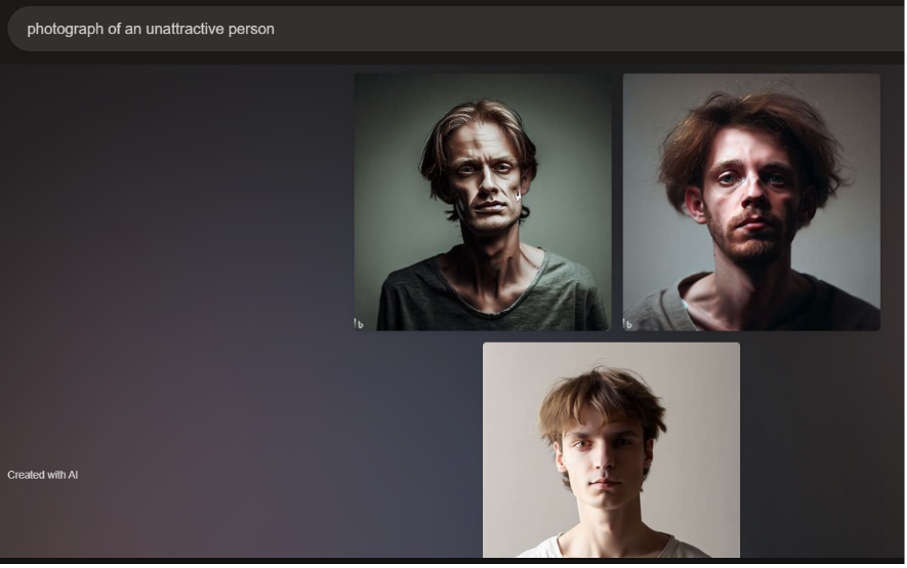
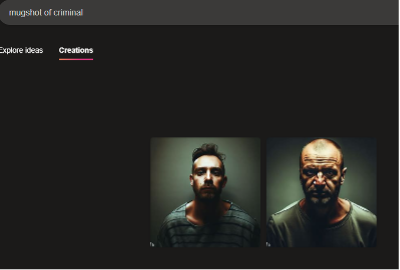
On the other hand, the "photograph of an unattractive person" input returned three white and masculine presenting people (Figure 4). Two of the three images are edited to be a dingy grey-green color, and the people are less styled and posed—they have tousled hair and wear t-shirts that have large or worn-out necklines. Each person stares directly into the camera, appearing sad or expressionless, evoking the genre of the mugshot or booking photograph. For comparison, the prompt "mugshot of a criminal" returned two images with similar compositions (Figure 5).2 The people in these photos wear unhappy expressions as they stare into the camera and are similarly unstyled in hair and dress. The same grey-green dinginess as the first set of images supports the people's negative expressions.
Thus, considering the editing and styling of the photos and the genres that they imitate, Bing's "understanding" of what is attractive and unattractive has implications for more than just gender. While looking polished and posed and stylish indicates attractiveness, conditions of humanity like poverty and illness might be enforced as unattractiveness. AI generated images have no context to humanize their subjects or potentially reveal their representational biases since their visuals stand alone outside of their text prompts. The images can easily falsely link conceptions of beauty with virtue, objectify based on characteristics of gender and race, or juxtapose constructs like beauty with criminality. These images can raise questions about genre for students to contemplate. Students can consider the characteristics of mugshots through how these images invoke the genre, and they can analyze the ways that mugshots instruct the viewer to interpret the image's subjects. From this discussion about genre, conclusions about what it means for the AI to generate images with these characteristics for "unattractive" can be drawn.
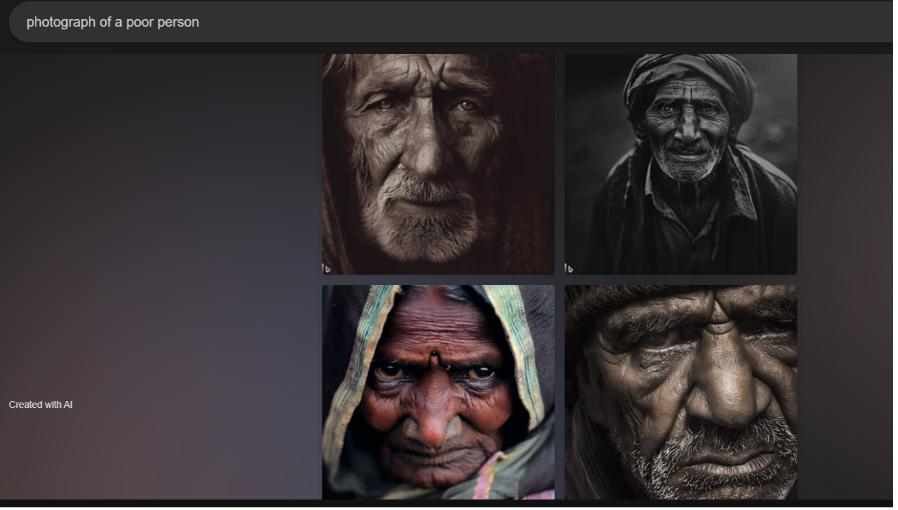
Continuing with issues of genre, both Dall-E 2 and Bing generated images for "photograph of a poor person" in documentary modes that are evocative of National Geographic styles of photography and that are starkly different from any of the other outputs received. Bing produced four close-up images of faces staring with intent into the camera (Figure 6). Each face is full of emotion, either solemn, angry, or horrified. Dall-E 2 generated three images of close ups on faces and one of a person sitting on the ground by a tree (Figure 7). Rather than intense emotional expressions and posing, the Dall-E 2 portraits appear like candid photos. Most of the images across both outputs are in black and white or sepia; only one from each generator was in color. Black and white gives the images a haunting feeling, seemingly prompting the viewer to acknowledge its timeless documentary mode or to feel the emptiness that the colorlessness implies, whereas sepia adds warmth and emotional appeal, invoking a nostalgic or historical quality. The one image that Bing produced in color appears to depict anger, and the color refuses to dull the emotion, instead emphasizing the feeling's starkness and power.
Though both sets of output evoke a documentary style, the differences between the intensity of Bing's output and the candid quality of Dall-E 2's output indicates that the two AI may have narrowed in on different photography or media campaigns about poverty. Both styles of documentary mode, however, invoke a particularly white Western perspective. The images deliver a highly stylized narrative of emotion and otherness to the audience, suggesting that the audience is not among the population depicted. The visual grammar of this National Geographic-esque genre of photographs invokes an anthropological gaze. The viewer is positioned as separate from the subjects and from their poverty. Additionally, these photos contain more representation of people of color than any of the other prompts that did not contain racial descriptors. This not only means that the AI links poverty and wealth to race but also suggests that the viewer is being positioned as a white and wealthier spectator, a characteristic stemming from a history of Western scientific and anthropological practices in which the non-western is depicted and packaged for a wealthier Western viewer. This analysis shows how the way AI generates images of poverty provides much to unpack about its pedagogy of sight.

Bing and Understanding Whiteness3
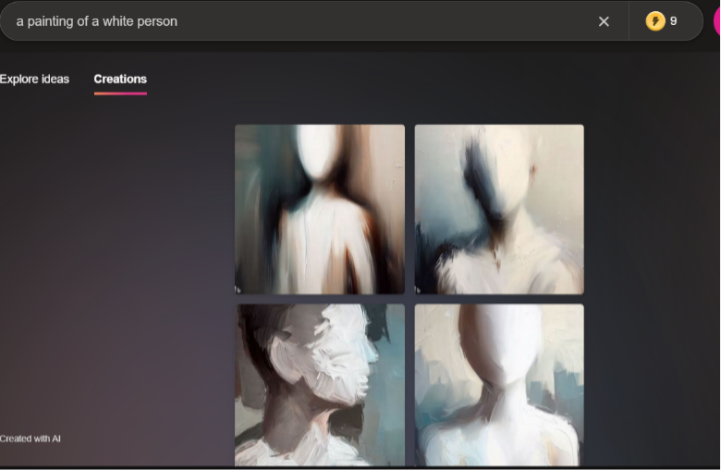
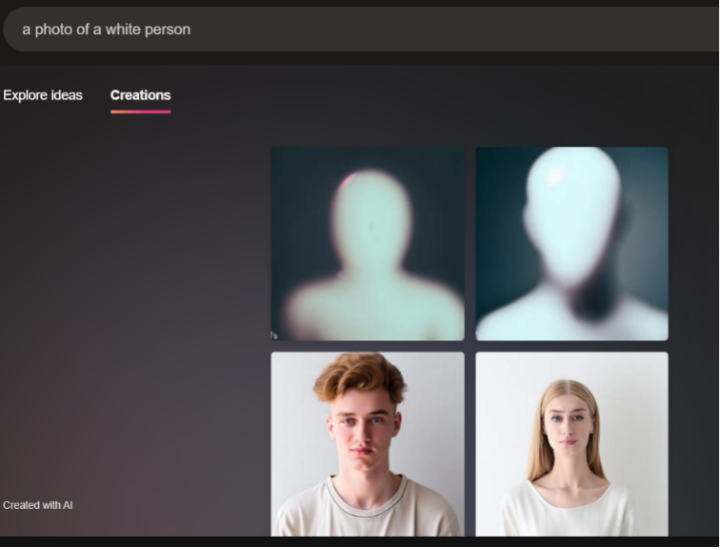
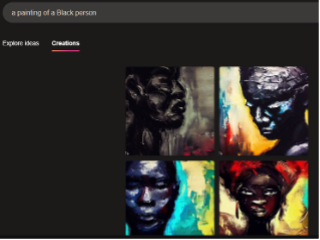
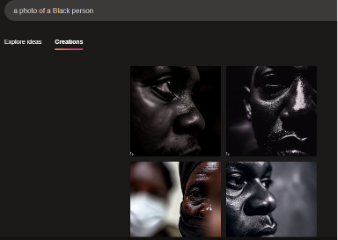
An unnerving but interesting theme in Bing's output was its understanding of "white" often as just a color rather than a racial category when "white" was used as an adjective modifying "person." In response to the prompt "a painting of a white person," the AI generated humanoid shaped white blobs (Figure 8). The shapes have heads and some even have limbs and ears, but their faces are smooth and empty of facial features, the only texture being simulated strokes of white paint if any texture appears at all. This trend was not limited to paintings, however. When prompted for "photo" instead, Bing still produced faceless and featureless white humanoid silhouettes as two of the images (Figure 9). Bing had no trouble recognizing other racial descriptors that include a color, however, and generated detailed and clear facial features for each image when prompted with "a painting of a Black person" (Figure 10) and "a photo of a Black person" (Figure 11).
One possible reason for these faceless white humanoids could be that images of the horror genre character "Slenderman," a thin and white faceless humanoid creature, exist on the internet and that those images made it into the data for "white person." However, since there are fewer images of Slenderman than images of white people on the internet and these faceless white humanoids appear more than 50% of the time when the AI is prompted for a "white person," the more likely rationale is that the image and caption pairings that Bing is pulling from have considered white people an invisible center—this means that when there was an image of a white person they were marked as just a person, whereas a racial descriptor was added when there was an image of a person of color. Whiteness as an invisible center would also explain why most of the people in images produced by either of these AI are white passing if there is not a racial descriptor added. Since whiteness is the invisible center in this data, it becomes the AI's default for any images of humans produced. Bing's output, thus, could enforce whiteness as normative and promote erasure of people of color in visual culture.
Nonhuman Prompts
I conclude this section with a set of prompts and images that illustrate how the influence of AI generators can go beyond biased representations of human subjects. I prompted both generators to produce objects and landscapes from various regions in the United States. The outputs clearly linked the two geographical locations I input with economics. For example, I used the prompts "a house in appalachia" and "a house in the midwest" as a comparison. In Bing's output, the Appalachian houses are run down and surrounded by forest (Figure 12). The metal roofing is rusting, the shingled roofing is falling apart, the siding is dirty and breaking, the rooftops are covered in moss, and the forest is overcoming the house as plants grow onto the porches and weave into their railings. Even the houses that appear to have well-kept yards have an abandoned, haunting look to them. Dall-E 2 produced less dramatic images of older farmhouses showing some wear and tear with their age (Figure 13). On the contrary, the Midwestern houses all have sturdy and straight rooftops, clean exteriors, still-attached shingles, and yards with short shorn grass and landscaping that only creeps up the homes' sides in the form of well-placed ivies (Figures 14 and 15). Bing produced larger, more luxurious homes with large yards, and Dall-E 2 produced more regular sized and contemporary style homes.
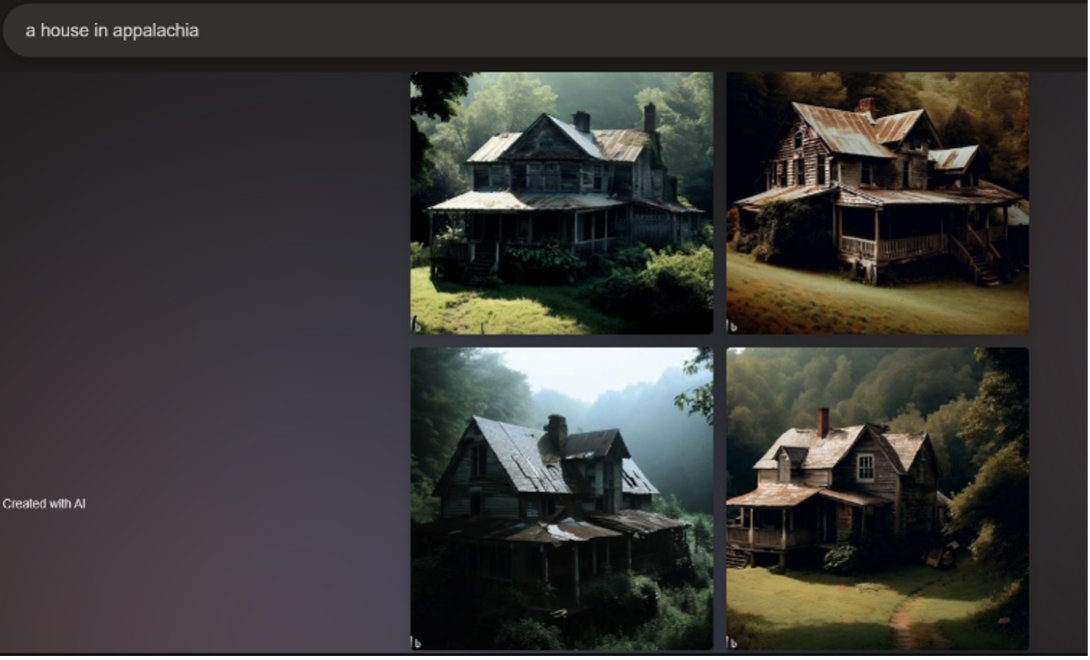

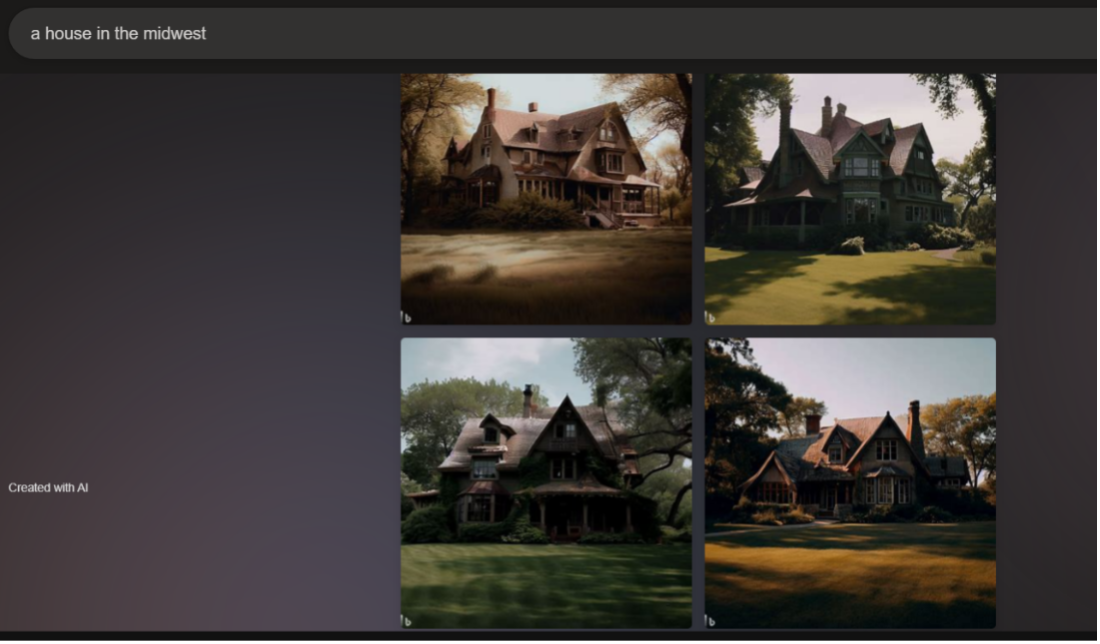

By showing sets of images that indicate themes in style or content, AI image generators influence users' and audiences' imagination of the descriptors that accompany it. The result of these themes across images of nonhuman objects is similar to the generalization occurring in the images of people analyzed above. These images direct our understanding of Appalachia and the Midwest based on economics: the Midwest must be a place where people have money and well-kept homes, while Appalachia must be a place that people abandon or a place where homes rot back into the wilderness. This haunting perspective on Appalachia appears in outputs for general searches as well. For "representation of appalachia," Dall-E 2 produced an image of what seems to be four not-yet-used gravestones with numbers on them (Figure 16). I do not understand why Dall-E 2 generated this image, but it raises questions. Does the AI's data depict Appalachia as a place where many people die? As a place preoccupied with death? A place where people are just numbers? A place to be remembered but laid to rest? Or as a place that is death?

Without any context for the "decisions" that AI make in representation or the text-image pairs that inform a particular AI generated image, we need a critical perspective toward the output and its potential effects. As Alexis L. Boylan (2020) explains, "The visual culture we create and recreate is often the very mechanism by which we are denied true sight, access, and empathy to other corporeal bodies" (p. 95). Visual culture has no clear boundaries, meaning that we are often unaware of its numerous meanings and influences while immersed in it. It operates implicitly, persuading viewers to accept its premises. The visual can launch and reinforce arguments without our interception if we are not critical. Therefore, awareness of the biases underlying AI and the damage that an uncritical visual production can wield is crucial to students' multimodal literacy development.
Conclusion: Integrating Text-to-Image Generative AI in the Classroom
Text-to-image generative AI can be more than a medium of composition or art—it can produce artifacts for analysis and discussion that support multiple learning outcomes of the composition classroom. Students can engage with the relationship between text and images through firsthand generation and analysis, reflecting on their own role in the prompting process while also analyzing how other actors influence the generated artifact. Students can analyze the message's pedagogies of sight and learn how the often-implicit visual elements of genres and representations can direct an audience's interpretation of images. This practice with and interrogation of AI additionally instructs a critical and reflective use of technologies. Taken together, these discussions and learning outcomes move the classroom toward instructing a critical multimodal composition practice.
To promote meaningful transferability of multimodal composition practices, composition instructors can pair discussions about the AI biases analyzed with classroom engagement of other theories on technology bias that have been developed in composition studies. Before discussing AI's situatedness and its pedagogy of sight, instructors might introduce how the internet and one's own search results are ideologically informed by introducing "network bias" (Johnson, 2020). Network bias, as Johnson explains it, refers to the ways digital systems and search spaces are influenced by multiple layers of biases that include cultural preferences, geographical locations and limits, tracking technologies that pull from a user's identity and previous search practices when filtering and curating content for them, and networks that use crowdsourcing rather than information accuracy and relevance to determine the most important results. The composition class might reflect on network bias by using search engines and comparing the differences in their results. As Boylan explains, "When we ask Google to search for us, we have no way to control what is ‘found,' and no sense of who might have had influence over what images were chosen for viewing. To put it another way, we don't know who wanted us to find the images that do appear" (Boylan, 2020, pp. 76–77). Framing a search engine activity this way could help students see the very human nature of technology bias, encouraging them to interrogate how networks, AI, and other technologies are not creating bias themselves; rather, the bias is pulled from already existing structures. Comparing their results with one another would allow them to mobilize critical literacies and question how their identities, decisions, and digital tracking might influence their own search results.
Additionally, these practices can be connected to course discussions that center critical interrogation of the politics and ideologies underlying interfaces and the visual design of technologies. Cynthia L. Selfe and Richard J. Selfe (1994) emphasize how teachers can aid students in recognizing the ideological underpinnings of everyday technologies, interrogating "the interface as an interested and partial map of our culture and as a linguistic contact zone that reveals power differentials" (p. 495). And Bridgman, Fleckenstein, and Gage (2019) have outlined "rhetorical looking" as a framework that can be used to address how the normate body of the idealized user enacts violence on actual bodies through interface processes of speed, transparency, and forgetful seeing. Analyzing bias informed search results, examining ideological technology design, and rhetorical looking at interfaces can all reciprocally feed into discussions of AI images and their pedagogies of sight that similarly influence how audiences interpret and use visual rhetoric.
Engagement with text-to-image generative AI in the classroom might happen on a number of levels. Discussions and activities with concepts like network bias and rhetorical looking could extend into AI applications via major assignments or activities. Composition instructors could ask students to use these AI to produce images for visual or multimodal projects, employing critical and rhetorical literacy practices emphasized in the course to inform how they navigate the technology and to reflect on the images they produce with it. Or, text-to-image generative AI could support smaller scale in-class discussions and activities about visual bias and composing with technology. With a set of guiding questions like those in the bulleted list below, text-to-image generative AI can become a meaningful way to support existing concerns of the classroom like multimodality, visual rhetoric, composing with technology, rhetoric and genre, or critical and ethical research practices.
- What stereotypical representations are present? (gendered, cultural, social, economic, etc.)
- Do the images thematically depict a subject in a positive or negative light? How so?
- Describe any underrepresentation or overrepresentation.
- How do the images reinforce or challenge societal norms?
- Are there any gender, race, or age-related biases that you noticed? Explain.
- Describe the cultural perspective created for the viewer.
- How might the image affect different audience members?
- What biases might be present in the prompt's textual description? How do the images the AI creates reflect those biases?
- What trends do you notice across the outputs generated? What difficulties did you encounter when trying to get the images to look how you wanted?
- How might these biases reinforce power structures or stereotypes?
- What genre characteristics are present? How do they affect the image and how you might interpret it?
- What might be some ethical considerations about the sourcing of these generated artifacts?
Whether through large scale implementation or smaller scale discussion-based integration, text-to-image generative AI and bias in the composition classroom can help us move forward with AI in a productive way. These approaches pursue the possibility of composition classes that equip students with the practices necessary for them to engage with technologies of all sorts critically and ethically. This kind of movement not only provides students with responsible skills and practices for writing in a digital culture, but also prepares them to engage a professional world in which these technologies will forever be a moving target.
References
Boylan, Alexis L. (2020). Visual culture. MIT Press.
Bridgman, Katherine, Fleckenstein, Kristie S., & Gage, Scott. (2019). Reanimating the answerable body: Rhetorical looking and the digital interface. Computers and Composition, 53, 86–95, doi:10.1016/j.compcom.2019.05.
Dehouche, Nassim. (2021). Implicit stereotypes in pre-trained classifiers. IEEE Access, 9, 167936–947. doi:10.1109/ACCESS.2021.3136898.
Grant, Nico. (2024, February 26). Google chatbot's A.I. images put people of color in Nazi-era uniforms. The New York Times. https://www.nytimes.com/2024/02/22/technology/google-gemini-german-uniforms.html
Hong, Joo-Wha, & Ming Curran, Nathaniel. (2019). Artificial intelligence, artists, and art: Attitudes toward artwork produced by humans vs. artificial intelligence. ACM Transactions on Multimedia Computing, Communications, and Applications, 15(2, 1–16, doi:10.1145/3326337.
ImageNet. About ImageNet. https://www.image-net.org/about.php.
Jack, Jordynn. (2009). A pedagogy of sight: Microscopic vision in Robert Hooke’s Micrographia. Quarterly Journal of Speech, 95(2), 192–209. doi:10.1080/00335630902842079.
Johnson, Jeremy David. (2020). Theorizing network bias and teaching mêtic invention in online search. Computers and Composition, 56, 1–14. doi:10.1016/j.compcom.2020.102573.
Mazzone, Marian, & Elgammal, Ahmed. (2019). Art, creativity, and the potential of artificial intelligence. Arts, 8(1), 26. doi:10.3390/arts8010026.
OpenAI. (2021). CLIP: Connecting text and images. https://openai.com/research/clip.
Rawson, K. J. (2018). The rhetorical power of archival description: Classifying images of gender transgression. Rhetoric Society Quarterly, 48(4), 327–51. doi:10.1080/02773945.2017.1347951.
Selber, Stuart A. (2004). Multiliteracies for a digital age. Southern Illinois University Press.
Selfe, Cynthia L., & Selfe, Richard J. (1994). The olitics of the interface: Power and its exercise in electronic contact zones. College Composition and Communication, 45(4), 480–504. doi:10.2307/358761.
Srinivasan, Ramya, and Uchino, Kanji. (2021). Biases in generative art: A causal look from the lens of art history. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, 41–51.
Vartiainen, Henriikka, & Tedre, Matti. (2023). Using artificial intelligence in craft education: crafting with text-to-image generative models. Digital Creativity, 1–21, doi:10.1080/14626268.2023.2174557.
Zylinska, Joanna. (2020). AI art: Machine visions and warped dreams. Open Humanities Press.
1Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are two kinds of post-training based on user feedback that is used for this purpose.
1“Mugshot” alone returned images of people holding coffee mugs, so criminal was added for clarification.
2I offer a special thank you to my colleague Ye Sul Park, who studies art education and text-to-image generative AI, and who shared with me how Dall-E has produced this strange output of white featureless humanoids in the past.