
The Black-Boxed Ideology of Automated Writing Evaluation Software
Antonio Hamilton University of Illinois Urbana-Champaign
Finola McMahon University of Illinois Urbana-Champaign
Introduction
The rise of Automated Writing Evaluation software (AWE) has had, and will continue to have, profound effects on writing classrooms in the 21st century. As a form of what writing studies now calls "artificial intelligence," AWE mediates student and instructor activity (Huang & Wilson, 2021; Wilson et al., 2021) as well as shapes student response in AWE-equipped classrooms (Wilson & Roscoe, 2020). Additionally, recent research has shown that the variation in mediated interfaces impacts students' perception of writing feedback (Laflen, 2023). Despite false promises of freeing instructors from the drudgery of responding to student writing (Haswell, 2006), AWE can have cold emotional consequences on student writers (Herrington & Moran, 2001). There are well-documented deleterious effects when machines are used to score student writing (Ericsson & Haswell, 2006). In fact, recent quasi-experimental studies find that AWE used for formative assessment does not improve student writing and may even worsen it (e.g., Ernst, 2020). Rather than focus on the broader effects of AWE machine scoring, we present a more narrow investigation into the mechanisms by which AWE rhetorically operate and how computational inner workings of AWE are often obfuscated, obscured, or black-boxed (Latour, 1987; Burrell, 2016). We qualitatively document the rhetoric of AWE software such as Grammarly, Outwrite, or ProWritingAid, including the claims these software companies make in their online materials. Doing so equips Writing Studies teachers with ways to argue against the jargon, rhetoric, and black-boxing deployed by AWE companies.
The rest of this chapter has five parts. First, we review the concept of black-boxing and its implications. Through this review, we generate our research questions. Second, we describe our methods, including the origins of this paper in our graduate seminar from the Fall of 2021, and the AWE we investigate, i.e., Criterion, Grammarly, MI Write, Outwrite, ProWritingAid, Paper Rater, WriteToLearn, and VirtualWritingTutor. Third, we present our findings that detail the features of these programs, the language used by the companies to describe the black-boxed "artificial intelligence", and the accessibility of the software programs. Fourth, we discuss these findings and their implications. Here, we note that these programs rely on an ableist ideology of ease, purposeful use of functional illiteracy, and hyperjargonizing. When new technologies are developed, we must grapple with their proclivity to have inherent bias against disabled bodies and learners, due to their often narrowly conceived audiences (Moura, 2023; Shew, 2020; Shaheen, 2021; Pengilly, 2021). After noting the limits of the study, we conclude that the language used by most of these software companies echoes current-traditional rhetoric approaches to the teaching of writing.
An Ideology of Black-Boxing
Black-boxing is at the heart of many computer programs. The following is general description of black-boxing, according to Latour (1999):
An expression…that refers to the way scientific and technical work is made invisible by its own success. When a machine runs efficiently, when a matter of fact is settled, one need focus only on its inputs and outputs and not on its internal complexity. Thus, paradoxically, the more science and technology succeed, the more opaque and obscure they become. (p. 304)
While Latour's work is well known in and outside Writing Studies, the key words in this passage are opaque and obscure, as they refer directly to machinic processes becoming settled, accepted, and overlooked. Writing studies scholar Francher (2021) develops a similar definition, writing "Blackboxing occurs any time complex technologies are used without questioning or understanding the design choices, thereby allowing the technology to be a mystery to the user" (par. 2). Both definitions highlight different aspects of black-boxing that we argue are operationalized in AWE. First, black-boxing is a structural force in Latour's conception; science and large-scale forces become successful and therefore do not need to explain themselves. Second, in Francher's definition, black-boxing is user centric, with design being foregrounded. With regards to AWE, black-boxing is both a centripetal and centrifugal force; it coerces users to think about technologies without critiquing them while the programmers can stand back and understand how the users are reacting to the program's force.
Black-boxing of this kind is thus highly ideological by means of opacity, a key concept elaborated upon by information scientist Jenna Burrell (2016). Burrell defines opacity as follows:
Opacity seems to be at the very heart of new concerns about ‘algorithms' among legal scholars and social scientists. The algorithms in question operate on data. Using this data as input, they produce an output; specifically, a classification (i.e. whether to give an applicant a loan, or whether to tag an email as spam). They are opaque in the sense that if one is a recipient of the output of the algorithm (the classification decision), rarely does one have any concrete sense of how or why a particular classification has been arrived at from inputs. Additionally, the inputs themselves may be entirely unknown or known only partially. The question naturally arises, what are the reasons for this state of not knowing? Is it because the algorithm is proprietary? Because it is complex or highly technical? Or are there, perhaps, other reasons? (p. 1)
For our purposes in this chapter, Burrell goes on to identify two ways that opacity functions to obscure or obfuscate understandings of black-boxes. First, opacity occurs because of proprietary reasons. Burrell writes, "The opacity of algorithms, according to Pasquale [2015], could be attributed to willful self-protection by corporations in the name of competitive advantage, but this could also be a cover for a new form of concealing sidestepped regulations, the manipulation of consumers, and/or patterns of discrimination" (p. 4). Writing Studies researcher Kevin Brock (2019) too has noted this defensive posture of companies in his book around rhetoric in computer code: "[software] services are simply used by consumers as black boxes rather than distributed to them as standalone programs. That is, it is possible—and often profitable—to build fences and walls around the ‘free' software supposedly accessible to any interested party" (p. 86; emphasis in original). To extend Burrell and Brock, proprietary reasons could be simply a function of capitalist competition or, more ethically dubious, an attempt to skirt governmental regulations.
Second, opacity can occur through technical illiteracy, or the framing of "...writing (and reading) code and the design of algorithms is a specialized skill" (Burrell, 2016, p. 4). Others in Writing Studies have noted the functional and mechanical biases of algorithms (Brock and Shepherd, 2016, p. 22; Charlton, 2014; Johnson, 2020). For example, black-boxing occurs because programmers do not wish to explain their mathematical models to laypeople.
While Burrell (2016) explains that opacity can also occur because machines process information differently than human beings (p. 4–6), we focus on the proprietary and technical illiteracy reasons. Following the idea that "Burrell's argument helps Writing Studies researchers to demystify algorithms when they are black boxed" (Gallagher, 2020, p. 3), we aim to examine AWE and the constitutive components through a qualitative investigation. More specifically, we want to "unbox" the black-boxes of AWE to reveal how some of their inner workings function. As such we propose the following research question:
- RQ1) What are the ways that AWE software companies black-box their software?
To answer this question, we set about analyzing the features, AI technology descriptions, and accessibility of these programs. Thus, our second research question is as follows:
- RQ2) What are the assessment features of AWE software and what are the commonalities and differences between them?
With these questions in mind, we began our process to potentially "unbox" and/or make the case for the "unboxing" of AWE programs that try to obfuscate their functionality for questionable reasons this chapter will explore. Understanding these moments of opacity within AWE programs will better help us to determine the place of automated writing software alongside or as an alternative to instructor-based writing assessment.
Methods
Description of course
This project began as a collection of midterms for a graduate seminar at University of Illinois Urbana-Champaign, titled English 584: Writing and Rhetoric in an era of Algorithmic Culture. The course examined the role of algorithms in contemporary culture, with a focus on writing and rhetoric. It asked students to critique procedures and instructions as they relate to writing processes and production. Students were asked to critique an algorithm of their choice and write two papers drawing on course texts and outside research. One of those papers was a midterm in which the three graduate students enrolled were asked to “unbox” three algorithms which were black-boxed in some way. As a result of the themes emerging during in-class discussions and the students' pedagogy related interests, all three students decided to focus on AWE algorithms. Following each students' individual process, described below, the three students, along with their professor, put the three midterm papers in conversation, drew conclusions across the data collected, and assembled the information to create this project. Additionally, two of the students selected VirtualWritingTutor as one of their objects of study. As a result, this project focuses on 8 AWE programs rather than 9.
The following data for this project was collected in the Fall of 2021. As such, these programs have likely changed and developed in the time since, especially with the launch of ChatGPT in the Fall of 2022. However, the concerns discussed, including the inconsistency of features and black-boxing of these algorithms continue to be relevant.
Narratives of data collection
Antonio Hamilton:
Once I selected Grammarly, VirtualWritingTutor (VWT), and WriteToLearn (WTL) as my three AWE algorithms, I developed a set of basic criteria by which I was going to assess each automated evaluation software. Because each of these AWE are intended for different audiences, I decided on identifying the elements listed below to determine what functions each AWE provided and how it performed those functions:
- Identifying the writing dimensionality AWE assessed (i.e., plagiarism, grammar, word choice, etc.)
- Type of feedback provided (if feedback was provided)
- The data used by the software's algorithm
- Other information about the software's algorithm, if provided.
I then created charts which cataloged and categorized the features and information that was discovered from each AWE website. After investigating each AWE's website for the four elements above, I developed further questions to send to the developers of the software in order to gather more information about the criteria if it was not apparent on the website or if their information remained obfuscated. Other questions were individually developed in regard to what was inductively discovered on each AWE's website. In the case of VWT, I conducted an interview with the creator where I followed up with the questions that were asked in my initial email to them. Questions and categorization of features were also accomplished by personally using the programs when the option was available. WriteToLearn, however, can only be used if purchased by a school's administrator; therefore, I could only infer based on the information provided on the website.
Finola McMahon:
My process began by selecting Criterion, Outwrite, and ProWritingAid (PWA) as the three AWE software I would analyze, in the hopes that they would cover three different approaches to AWE. Criterion is strictly academic and accessible only through schools and universities. ProWritingAid is more publicly available, although it still primarily targets professional or academic contexts. Outwrite is not framed as targeting a specific audience. I hoped that these different approaches would create a picture of AWE software overall. With these audiences in mind, I identified the following elements:
- The features and functions of each AWE, including descriptions
- The assessment claims of each AWE
- The feedback provided by each AWE and, if so, the form of the feedback
- Explanations of the algorithm
To do so, I read through each program's website and made note of the companies' explanations of their intended audience and use, as well as what their algorithm does and how it accomplishes its goals. During this process, I paid particular attention to any static abstractions (Connors, 1997), or the way in which stylistic terms coalesce to become static (p. 265–6), the company used or referenced. I explored articles and documents published about the three programs. This mostly provided information about Criterion, as it has been researched previously and Criterion's parent company, Educational Testing Services (ETS), has published a great deal of explanatory documents about their program. Throughout this process, I tested the free versions of the programs whenever possible and made note of the user experience to further address the above questions, particularly in #3 above. Finally, once my co-researchers and I began to compile our data, I identified specific features or program details they had collected that I had not. Using that information, I returned to the companies' websites and program interfaces in search of the correlating information for my algorithms.
Alexis Castillo:
To begin my research of AWE algorithms, I chose three types of AWE software: Virtual Writing Tutor (VWT), Paper Rater, and MI Write. VWT and Paper Rater are the more student-friendly of the three programs whereas MI Write is marketed to administrators and teachers. Setting out to consider these programs from the perspective of a student and high school teacher, the following topics were the basis of my analysis:
- Accessibility of each program
- Scoring features offered by each AWE software
- Actionability and source of written feedback (when provided)
- Risks of using AWE programs in the classroom
- Alignment of teacher and AWE software learning objectives
After selecting what I would assess, I attempted to use each program, but because MI Write was paywalled, my engagement with VWT and Paper Rater was more extensive. I was able to immediately insert a writing sample for evaluation into VWT and Paper Rater. Once the sample was evaluated by each of the programs, and in the case of Paper Rater, scored, I considered the features the programs promised to evaluate alongside the feedback the programs actually generated. With the goal of understanding how feedback was produced and the software developer's intended uses for these programs, I reached out via email to the contacts listed on the websites. After making contact with the VWT developer and a MI Write representative, I gained insight as to what degree each evaluation tool could be personalized to match a teacher's learning goals and the objectives that the companies had in mind when creating the programs.1
Themes of Black-Boxing
Theme 1: black-boxing occurs through inconsistent features
Table 1: Assessment Features Organized by Automated Writing Evaluation Program
| Features | Automated Writing Evaluation Program | |||||||
|---|---|---|---|---|---|---|---|---|
| WriteToLearn | Grammarly | Virtual Writing Tutor | Criterion | ProWritingAid | Outwrite | Paper Rater | MI Write | Plagiarism Checker | X | X | X | X | X | X |
| Grammar | X | X | X | X | X | X | X | X |
| Punctuation | X | X | X | X | X | |||
| Spell Check | X | X | X | X | X | X | X | X |
| Conciseness/Cohesion | X | X | X | X | ||||
| Word Choice/Vocab | X | X | X | X | X | X | X | X |
| Word Count | X | X | ||||||
| Tone | X | X | ||||||
| Formality Level | X | X | X | |||||
| Fluency | X | X | X | X | ||||
| Clarity | X | |||||||
| Topic Sentence | X | X | X | |||||
| Check Paraphrase | X | X | ||||||
| Sentence length/variance | X | X | X | X | ||||
| Argument Strength | X | |||||||
| Thesis | X | X | ||||||
| Audience Checker | X | X | X | |||||
| Domain | X | |||||||
| Redundant content | X | X | X | |||||
| Conventions | X | X | X | |||||
| Organization | X | X | X | |||||
| Ideas | X | |||||||
| Extraneous Information | X | |||||||
| Passive Voice | X | X | X | |||||
| Pacing Check | X | |||||||
As shown in Table 1, the features offered by the eight programs varied widely. Of the 24 features identified, only three appeared across all eight AWE: "Grammar," "Spell Check," and "Word Choice/Vocab." These more traditional features tended to be left self-explanatory or were defined briefly. By leaving these terms' definitions to the user's interpretation, the features are still black-boxed due to the lack of specificity. For example, "Grammar" and "Spell Check" may appear to be more universal at first glance. The definition of 'correct' grammar can vary based on context, language, and audience, but each program largely implements the category to encourage use of current-traditional Standard Edited American English (SEAE) grammatical norms, such as syntax and morphology. "Spell Check" is an easier feature to define, with each program generally encouraging the use of SEAE spelling (Conference on College Composition and Communication, 1974). "Word Choice/Vocab" is less clear as the target audience and goals of each AWE vary. For example, WTL and MI Write are targeted towards K-12 versus VWT which is targeted towards English as a Second Language (ESL) students. The creator of VWT, Nicholas Walker, provided the most direct insight into the function of "Word Choice/vocab" as a feedback feature. As he was designing the software for use in his own ESL classroom, he identified words commonly used and commonly misspelled by his students and programmed the algorithm to pay particular attention to those words, rather than relying on machine learning to identify those themes independently. While "Grammar," "Spell Check," and "Word choice/Vocab" were included features in all eight programs, they were not all rhetorically positioned in the same way. Beyond the three features present in every AWE, two additional features were present in the majority of programs: "Plagiarism" (6/8 programs) and "Punctuation" (5/8 programs).
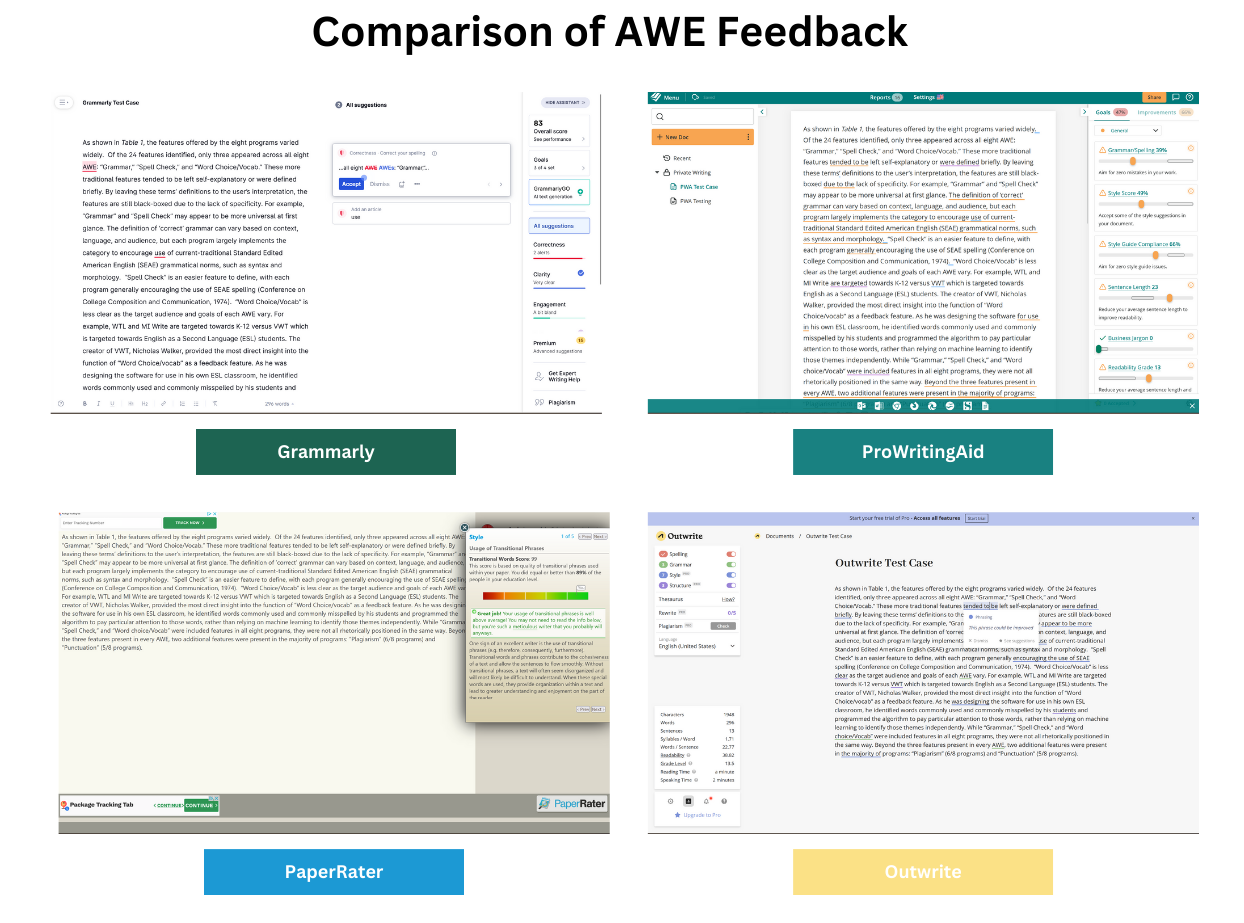
If we consider the unacknowledged inconsistencies of similar/identical features across AWE, AWE are collectively black-boxed. In particular, the rest of the features noted were included by four or fewer AWE. Some of these features were not clearly defined and in cases such as MI Write and Criterion, where the feature was behind a paywall, we were unable to determine the criteria upon which the feature was based. Examples of this included "Extraneous Information" from WTL and "Organization" from MI Write, Criterion, and WTL.
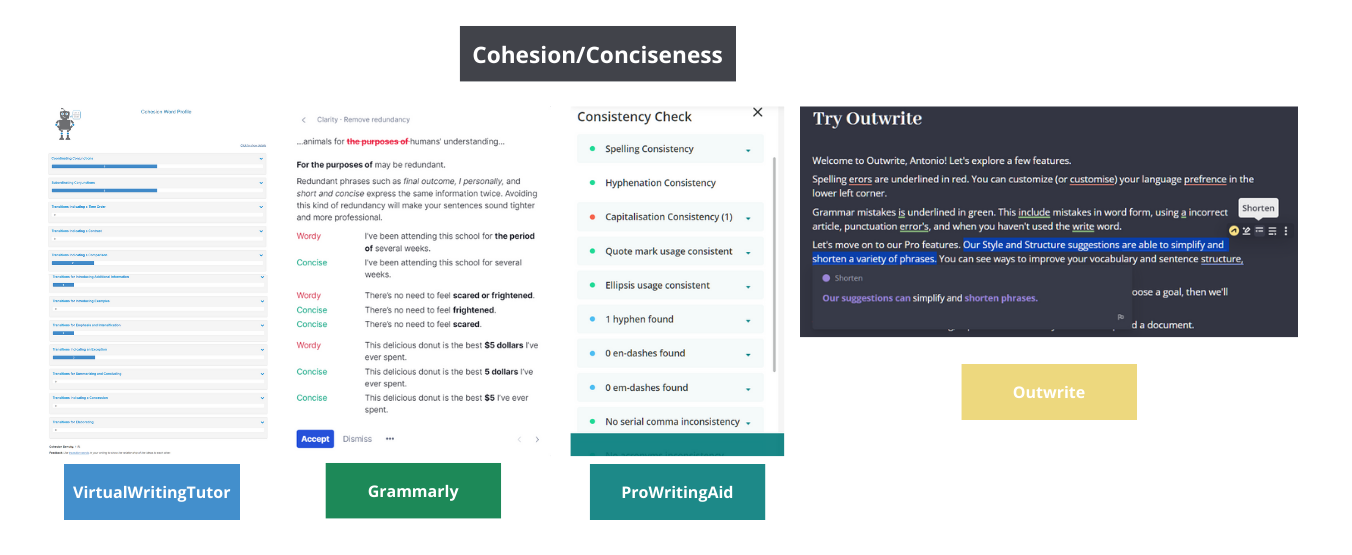
To further highlight the disparity in features across AWE, we note the way that the "Cohesion/Cohesiveness" feature functions across programs. While this feature is included by three AWE, each used the feature differently. VWT defined "Cohesion" based on transition words, such as "transitions indicating time order," "contrast," "cause and effects," etc. Grammarly appears to assess "Conciseness" based on efficient phrasing, they provide the example of "There are some who argue that Macbeth is an antihero, not a villain," with Grammarly providing the suggestion that "There are some who argue" be changed to "Some argue." PWA defined the feature based on many types of consistency, such as "spelling consistency," "hyphenation consistency," and "capitalization consistency." The "Cohesion/Cohesiveness" category functions as a clear example of a static abstraction, used by multiple programs for very different purposes. The implications of these inconsistencies will be further explicated in our discussion section.
Theme 2: black-boxing occurs through hyper-jargonizing
Table 2: Definitions of AI Technology Organized by Automated Writing Evaluation Program
| AI TECHNOLOGY CHART | ||
|---|---|---|
| Program | Type of AI Used | AI Technology Definition (described by the website) |
| WriteToLearn | Latent Semantic Analysis | "The KAT engine is based on the mathematical approach known as Latent Semantic Analysis (LSA), which provides a sophisticated computer analysis of text" (Grammarly). |
| Knowledge Analysis Technologies | "The KAT engine evaluates the meaning of text by examining whole passages. The KAT engine is based on Pearson's unique implementation of Latent Semantic Analysis, an approach that infers semantic similarity of words and passages by analyzing large bodies of relevant text. LSA can then understand the meaning of text in much the same way as a human reader" (Grammarly). |
|
| Grammarly | Natural Language Processing |
No definition is provided, only multiple articles that give an overview that they use NLP. |
| Virtual Writing Tutor |
Latent Feature Analysis | "I have developed a special method of quality detection that I call Latent Essay Feature Analysis (LEFA). I use it to discover what makes a great essay great" (Walker). "First we extract and measure a range of latent features from a model essay: the organization, cohesion devices, vocabulary choice, and writing quality. Those measurements are stored in the database as a series of targets" (Walker). |
| Model Essay Proximity Scoring | "Then, I use Model Essay Proximity Scoring (MEPS) to determine how closely your essay resembles the ideal essay response for each test prompt" (Walker). "When a student submits an essay on the same topic, it measures those same features and generates a proximity score. How close is the submitted essay to the ideal essay? The feedback and band scores tell you how close you are to the ideal" (Walker). |
|
| Criterion | Natural Language Processing | An area of computer science and AI design "concerned with giving computers the ability to understand text and spoken words" through a use of "computational linguistics […] with statistical, machine learning, and deep learning models" (IBM Cloud Education, 2020) |
| E-rated Scoring System |
A specific NLP based system created by ETS. This system is used across many ETS applications and tests. |
|
| ProWritingAid | Natural Language Processing | An area of computer science and AI design "concerned with giving computers the ability to understand text and spoken words" through a use of "computational linguistics […] with statistical, machine learning, and deep learning models" (IBM Cloud Education, 2020) |
| Outwrite | Unspecified | N/A |
| Paper Rater | Ginger | "Ginger corrects mistakes, but also gives explanations, language tips and personalised advice to improve your writing and style. It also suggests alternative ways to express your ideas with AI-based Synonyms and a Rephraser that works like a thesaurus for whole sentences" (Ginger Software). |
| MI Write | PEG (Project Essay Grade) | "As with most automated scoring software, PEG utilizes a set of human-scored training essays to build a model with which to assess the writing of unscored essays. Using advanced statistical techniques, PEG analyzes the training essays and calculates more than 500 features that reflect the intrinsic characteristics of writing, such as fluency, diction, grammar, and construction. Once the features have been calculated, PEG uses them to build statistical and linguistic models for the accurate prediction of essay scores. MI enhances scoring accuracy by using extensive custom dictionaries and word lists, producing results that are comparable to MI's well-trained and expert human readers" (Measurement Incorporated). |
Similar to the inconsistencies in the "Cohesion/Cohesiveness" feature, there were operationalized words without referents with unclear definitions used by the companies in their descriptions of the technology used to power AWE software, otherwise known as jargon. Hirst (2003) notes the negative impact that jargon can have as it is often defined negatively as "the pretentious, excluding, evasive, or otherwise unethical and offensive use of specialized vocabulary" (p. 202). This use of jargon was present in the features and interfaces of the programs, as well as the promotional and informational material about the AWE, often including generalized definitions of the AI Technology used, which can be found in Table 2. For example, Grammarly noted that their software uses "Natural Language Processing" (NLP) but does not define the type of NLP used. They instead provide the general term, relying on jargon to black-box their software. Similarly, each of the algorithms' interfaces relied on static abstractions to categorize the features they studied, without providing details of what exactly the feature was calculating. For example, four of the AWE claim to calculate "Fluency" but there is no explanation of what that term means or how it is calculated.
Outwrite stands out slightly in comparison to the other programs in that they provide no details on their software's programming. While the other programs provide information in general terms (e.g. stating that they use "Natural Language Processing" or "Latent Semantic Analysis"), Outwrite makes no attempt to clarify the programming process.
Additionally, Grammarly, PWA, and Criterion appear to attempt to "unbox" their software by providing a wide variety of articles about their features and software. Grammarly and PWA's articles spoke in very general terms about technological possibilities in AWE and writing feedback, without specific grounding in their use. They housed these articles on their websites, while Criterion has many published academic articles about their software and their scoring system (used across multiple ETS services). Notably, these AWE are all targeted at schools and academic settings. The more public-facing, less academic programs did not provide the same level of attempted transparency.
Theme 3: Black-boxing occurs through proprietary and subscription services
Table 3: Access Organized by Automated Writing Evaluation Program
| Program Accessibility | |||
|---|---|---|---|
| AWE | Paywall | Access | Target Users |
| Write To Learn | Paywalled $14.95 per student each year $3500 for full day training $1500 for half day training $300 for consultation |
No access, must purchase to use | Students started from 4th grade to 12th grade (Administrators have to purchase) |
| Grammarly | Partial Paywall Free – for individuals that only want spelling grammar, punctuation checked Premium ($12.00/month) – for individuals that want all of Grammarly's assessment features Business ($12.50/member/month) – For companies looking to use Grammarly for 3-149 individuals |
Access to the free version, but must download and install Grammarly into the software you wish to use it for | Targeted towards everyone, but also students and businesses |
| Virtual Writing Tutor | No Paywall Non-members can have 1000 words assessed Members (which is free) can have 3000 words assessed |
Instant access, can immediately paste writing or type text into text box | Targeted towards ESL, students primarily |
| Criterion | Paywalled grade level, the number of students using the program in a class, and the number of essays assessed |
Program access upon payment (only purchasable through a school)(Web-based service, used through the ETS Criterion website) | 3 categories: k-12 students, higher education students, "global customers" |
| ProWritingAid |
Partial Paywall Free Premium - $79/year (or $20/month, $399 for lifetime) Premium+ - $89/year (or $24/month, $499 for lifetime) |
Immediate access (Multiple access options: their website, a browser extension, a plug-in for word processors, and a desktop app) | Targeted towards everyone, but also students and businesses |
| MI Write | Paywalled (Quote not obtained) |
Demo access upon formal, request Program access upon payment | Students grades 3-12 |
| Paper Rater | Partial Paywall Free Readability indices only available to premium members for $7.95/month |
Immediate Access | Grades 1-12, undergraduate students, masters students, PhD students, and other |
| Outwrite | Partial Paywall Essential – Free Pro – $9.95/month for yearly (or $24.95/month for monthly) Teams – $7.95/user/month for yearly (or $14.95/user/month for monthly) |
Immediate access (Multiple access options: their website, a Chrome extension, an Edge extension, a Google docs add-on, a Word add-in, and an API proofreader) | The general public and corporate writers |
Note. This chart presents information on how individual users are able to access the services of the programs via paywall options and each AWE's reported target audience.
VWT is the only AWE we studied which is completely free. It includes a two-tiered system of members and non-members, both tiers are free. They limit the word count to 1000 words for non-members and 3000 for members. Conversely, MI Write, WTL, and Criterion are all fully paywalled, providing no free option. They also happen to all target academic audiences specifically, and all three must be purchased through a school. Outwrite, Grammarly, Paper Rater, and PWA all provide tiered options allowing for free use with limited features or paid use with additional features. Additionally, PWA is the only one of the services which offers a lifetime purchase option. For each service which provides at least one free option, listed in Table 3 above, users can access the software immediately, though some require users to sign in. Conversely, MI Write, WTL, and Criterion do not provide any way to view or interact with their interface on their websites. Only MI Write provides an option to request a demonstration. This means that users have limited options for testing the software, and no option in the case of WTL and Criterion, further obfuscating and black-boxing the algorithm. This obfuscation allows fully paywalled programs, such as these, to control the narrative of how their software is perceived by potential users. Since users cannot create their own narratives based on their direct experiences without the influence of the creators, the algorithms are further black-boxed. In the process, the creators perform a perceived transparency while limiting independent access to the AWE.
In the tiered payment systems, certain features are restricted to paying customers only, such as "Plagiarism" checks. All four of the tiered AWE provide "Plagiarism" as a service, but not for free. Outwrite and Grammarly provide "Plagiarism" checks to paying customers while Paper Rater and PWA provide users with tokens they can use to check, with paying tiers receiving a certain number of tokens to start and free users paying for tokens when needed. Many of the features provided for paid tiers alone were focused on higher level writing concerns, like "Tone Suggestions" for Grammarly and "Sentence Rewriting" for Outwrite.
Discussion
As we stated previously, AWE mediates student and instructor activity (Huang & Wilson, 2021; Wilson et al., 2021). As such, it is vital to document the functions and affordances of AWE, so that we can utilize AWE to its fullest potential, while addressing the issues these technologies might create. Even if the functions and affordances change, our themes highlight the inconsistency and black-boxing in the creation of Automated Writing Evaluation Programs.
We found that black-boxing occurs through inconsistent features, such that users cannot compare across programs or expect two programs to provide consistent feedback to the same input. The programs studied also made use of undefined terms, classified here as jargon, which limited a user's ability to understand the feedback they are given, even as the AWE may appear to explain its output. Finally, the programs' use of tiered subscription services limits testing prior to use, further black-boxing the AWE.
Discussion Point 1: Technical illiteracy is used to appeal to audiences who can buy software, such as school administrators
Notably, VWT became slightly less black-boxed for us specifically, as a result of Nicholas Walker's willingness to discuss his program directly and explain the process he used. We might also note that Walker is a teacher who was designing VWT with his own students and colleagues in mind. His willingness to share the details of his project may be related to the fact that he is not a corporation trying to develop a software for profit, but a teacher trying to better serve his students. Protecting proprietary materials may not be a priority to Walker in the way it is to a corporation like ETS. While the issue of technical illiteracy (Burrell, 2016) might not allow many users to truly understand how VWT functions, Walker's willingness to share the details of his program's creation does help in the "unboxing" process
However, other programs create black-boxing via assessment terminology. The AWE's use of jargon and the naming of different 'assessment categories' function as a form of black-boxing through functional or technical illiteracy. When WTL says that they check for "Extraneous Information," there is no clear way to tell what that actually assesses from the name itself, it is company-specific jargon. (Because WTL is behind a proprietary paywall, users cannot even test for what the category is looking for unless they are a paying customer.) If users cannot understand the feedback feature due to the jargon used, they cannot fully understand the feedback they are given and will not be able to critically apply the feedback to improve their writing.
This issue extends to the assessment terms which users might assume are commonly understood, such as "Grammar." Because the AWE do not provide definitions of these terms or hide those definitions behind a paywall, an administrator purchasing the program may expect that the use of the assessment terms matches their expectations. In the case of "Grammar" specifically, purchasers are left to assume their own meaning of the term, allowing the programs to obfuscate the complexity of grammar and the existence of different forms of English or the existence of global Englishes. These algorithms actively hide the truth that there is no one universal grammar, but many different rule sets for English grammar (Conference on College Composition and Communication, 1974). This could result in an AWE being utilized to prioritize white Englishes, and if administrators are unaware of the way grammar is being defined, they cannot account for or address that prioritization, potentially resulting in the continued centering of white language in education. Even when definitions are provided, they lack consistency and are implemented differently across different AWE. This further emphasizes that when the assessment categories appear to be easily understood, like "Grammar," they are still slightly opaque. It would be easy for many users to look at that category and imagine grammar as a standard, universal set of rules, but the simplicity of the assessment term in many of these AWE hides the underlying questions of the many types of Englishes used around the world and within countries and communities.
This lack of concrete definitions continue to be an issue even in the case of the AWE's "Plagiarism" checkers, which should arguably result in straightforward feedback. The "Plagiarism" checkers included by the AWE in the study theoretically must have a vast data bank of sample texts to compare student writing against. However, at the time of our data collection, none of the AWE studied provided information on what that sample input included or how it was collected. Are they scanning the internet to check for uncited repetition? Do they save past papers to compare against? This becomes an issue because it is hard to understand how the "Plagiarism" check might be functioning, as well as the effectiveness of a "Plagiarism" checker. Additionally, there is the question of exactly when something is considered plagiarism. If a student quotes something but has an error in their in-text or end-of-text citation, will the AWE consider that to be plagiarism? (And if so, how are they determining what the 'correct' citation would look like, given the common errors and issues in online citation generation programs.) The amount of paraphrasing a writer would need to avoid potential plagiarism may vary depending on the AWE used. The programs provide no information about the input involved in their "Plagiarism" checker or its functioning, further black-boxing the software and complicating its use. The answers to these questions are exceptionally important, given that the majority of these AWE target academic audiences, at least in part. If the "Plagiarism" checker is not accurate or does not mirror the plagiarism assessment of a student's teacher, they could be punished for plagiarism in a situation where they thought they had cited appropriately. This issue with plagiarism checkers is representative of a larger issue with the lack of information on the feedback features and what is shaping the feedback output.
AWE's common use of occluded terms extends to descriptions of the coding processes, including the use of the industry term "Natural Language Processing," which functions as undefined jargon and uses the technical illiteracy of AWE's users to limit their understanding of what they are getting from the program. Talking around what NLP actually is and how they are utilizing it allows the AWE to situate itself as innovative. Criterion, PWA, and Grammarly all specify that their programs use "Natural Language Processing," but do not provide detail about the type of NLP used or the databases used as sample input. For example, ETS offers an about page for their e-rater scoring engine, which is used for a number of ETS programs, including Criterion. They note that the e-rater system "uses AI technology and Natural Language Processing (NLP) to evaluate the writing proficiency of student essays by providing automatic scoring and feedback" (https://www.ets.org/erater/about.html). When users click on the "how it works" tab of the page, they are informed that the engine builds on "nearly 2 decades of Natural Language Processing research at ETS," but there is no clarification of what those two decades of research entail, what NLP actually is, or how their version was developed (https://www.ets.org/erater/how.html). They provide enough information to give the appearance of transparency, but the information provided does not explain the way the NLP is used or developed. They trust that the reader likely will not know enough about NLP to ask those questions, relying on jargon to keep people situated in a place of technical illiteracy without even realizing their situation. This can be seen as a form of manipulation for users to buy into the service because the AWE is presented as having innovative, extraordinary capabilities through the framing of the term "Natural Language Processing." That is not to say these programs are not innovative or extraordinary, simply that NLP can be an occluded term for individuals without a technical coding background.
Discussion Point 2: User design and circuitous website navigation is used to black-box user understandings of AWE. Writing suggestions are circular in their explanations.
This question of black-boxing also ties back into the rhetorical choices made by the program. The use of jargon is not accidental, it is an active rhetorical choice. This is especially clear when considering that many of the programs did provide descriptions of their assessment categories, but the descriptions were often not helpful in understanding what the program was actually looking for.
For example, PWA includes a "Pacing Check." The info button on the check provides feedback such as "Your document's pacing is engaging. Click this button to learn more." Followed by the description below:
"Pacing refers to the speed at which a story is told and how quickly the reader is moved through events. If you have too many slower paced paragraphs in a row, your writing may be boring. Good writing contains faster-paced sections, such as dialogue and character action, as well as slower-paced sections, such as introspection and backstory. Read More > (Pacing)

Both the "Info" button and the "Read More" lead the user to the same webpage, which describes pacing in a novel in abstract terms (see image 3). It includes sentences such as "Pacing refers to the speed at which a story is told and how quickly the reader is moved through events. If you have too many slower paced paragraphs in a row, your writing may be boring" and "By visualizing and understanding your document's pacing, you can decide whether or not it is effective for a specific section." While the article provides theoretical descriptions of the concept of pacing, it does not explain how that is calculated in any way. Beyond "visualizing and understanding your document's pacing," the article does not explain how someone would go about understanding the pacing of their writing nor how the algorithm calculates a score based on the concept.
Connected to this is the inconsistency of the use of certain terms across programs, including the concept of "Consistency," which was used by some programs in very similar ways. As we described in our findings section, VWT, PWA, and Grammarly all used the concept differently. They did not use the same measurement to address the concept. Notably, in the case of PWA, they provide various "Consistency" checks, but unlike many of their other checks, they provide no description or explanation for what the check is looking for or what "Consistency" means in this context. This inconsistency prevents users from getting a sense of what their feedback means or how the algorithm functions, even in the case of terms that appear across programs.
Discussion Point 3: Black-boxing occurs through appeals to current-traditional rhetoric and static abstractions
The inconsistency in the use of certain terms is partially related to AWE's general use of static abstractions. The term static abstraction refers to the words or phrases intended to provide feedback on styles of writing which become abstracted such that their specific meaning is unclear (Connors, 1997, p. 269). Traditionally, static abstractions would include terms such as clearness or unity, which may invoke the feeling of a specific meaning, but cannot really be quantified or explained in practical terms. We suggest AWE run on static abstractions: "Cohesion" is a static abstraction, and as a result, it is not defined or used consistently across programs. Other static abstractions that appeared frequently include "Word Choice/Vocab," "Fluency," "Formality Level," and "Tone."
Additionally, through their use of static abstractions and their lack of explanatory materials or tutorials, the programmers are engaging with an ableist ideology of ease. They approach their programs with the idea that all users will engage with the program in specific, narrow ways, expecting “the individual to [change to] fit the environment rather than the other way around” (Shew, 2020, p. 48). In doing so, they are making narrow assumptions about their audience, which could make their product inaccessible to some users. And beyond the question of if it is accessible once in use, the companies are also assuming that users will come to these programs with specific experiences and knowledge and will be able to figure out how to use the program in the first place. The black-boxing that these companies do, means that they do not have a lot of explanatory material guiding users through the program. To assume that everyone will come to the program knowing how to engage and interested in that specific form of engagement is rooted in ableist ideas of a uniform human experience. Ultimately, our analysis of the features that are assessed by the AWE are typically focused on upholding and perpetuating proponents of current traditional rhetoric (CTR) as defined by Berlin (1980). These CTR components predominantly emphasize sentence structure, syntax, spelling, punctuation, and style. The eight AWE and their features directly reflect these concerns if we look at the features that most of them had in common: "Grammar," "Spell Check," "Punctuation," "Word Choice," and "Cohesion." Even the features that were not common amongst the majority of AWE still highlight a focus on current traditional rhetoric: "Sentence Length/Variance," "Organization," "Formality Level," "Clarity," and "Fluency." These concerns about CTR's focus on effective written communication can be seen in studies that focused on uncovering if AWE can assist students with improving their grammar (Laio, 2016; O'Neill & Russell, 2019; Lee, 2020). In these studies, they found that their AWE under investigation can help students improve their grammar, further highlighting the primary utility of AWE—to assert CTR as its primary function. We can also infer that this is the focus due to the "basic assumption about how natural language works, namely, that language is linear on the surface and this linearity is determined by grammar. Thus, if researchers could construct all the rules that dictate how 'elements in well-formed sentences' may be combined, then in principle those rules may be translated into the artificial language of computers" (Ericsson & Haswell, 2006). The majority of these programs are not concerned with (and potentially not capable of addressing) the intellectual content of the writing it is assessing. They do not provide feedback on how to develop one's ideas or if an idea is logically sound. These algorithms provide feedback based on a set of rules and choices that the programmers have selected. The feedback has to be centered on linearity of sentence structure.
Therefore, because writing is a "socially embedded process," we would "question the ability of AWE software to judge critical thinking, rhetorical knowledge, creativity, or a student's ability to tailor their text to a specific readership" (Hockly, 2019). Appealing to different audiences requires an understanding of the complex web of conventions that are not beholden just towards the way something is written. The AWE that claim to assess audience are pigeonholing genre to distinct word choices and linear constructions of phrases, instead of content. In this way, genres become rigid and one-to-one relations that ignore the fluidity of typified occurrences. Because linearity is the primary capability of AWE, it is more suited to assess structures of writing that closely align with CTR outcomes. Higher level writing concerns, such as "Ideas," "Extraneous Information," and "Organization," are primarily available if the individual subscribes to a paid tier of the AWE. These higher-level concerns supposedly may assist in helping the individual with components of writing that move beyond just sentence structure, such as: argument strength, extraneous information, thesis, and attention to audience. The features that are free are aligned with concerns of CTR.
It is worth noting how CTR features are abundant across multiple AWE we analyzed, while "higher level" writing concerns are not. Speculatively, this too calls into question the capability of these features if multiple AWE do not see these as common concerns for writers. Questions arise from these observations: Are programmers reifying CTR? Are they merely reflecting writing assessment trends in the classroom? Is there another cause of this trend? Whatever the reason, the outcome remains the same, the intention of these AWE is black-boxed, obfuscated, and occluded.
Limitations to the study
The sample size of the AWE analyzed is not exhaustive, therefore, statistical issues exist in our claims. However, this was not meant to be an exhaustive study of all AWE; it was intended to be a preliminary study to gather insight of potential intersections for research. Due to the small sample size, the data is only based on these specific AWE that were selected by three researchers. In this, there potentially lies implicit bias as no unifying strategy was developed for the selection process of the AWE. It should also be considered that this data was gathered in Fall 2021, prior to the release of ChatGPT and the increased use of Generative AI incorporated into AWE and word processing technologies. An initial review of the data in Summer 2023 shows that there seemed to be few significant changes in the services provided by the AWE studied. However, this was a cursory review and further research on the impacts of Generative AI on these programs should be conducted.
Additionally, this was not a funded study, so the paywalled AWE prohibited us from testing certain features or interacting with the AWE interfaces. Specifically, we were unable to use Criterion, WriteToLearn, and MI Write in any capacity since they were completely paywalled. Therefore, any claims asserted or data gathered from these three AWE were based on information provided on their home websites.
Conclusion: Unpacking the Black-Box
If we recall Ernst's (2020) assertion that "AWE used for formative assessment does not improve student writing and may even worsen it," it underscores how when it comes to the black-boxing of the AWE, we do not know what guides the assessment choices concretely. In our study, we found it difficult to know how the AWE is assessing writing (and when we consider this assessment being applied differently across programs, this difficulty increases exponentially). This lack of knowledge could be why AWE may worsen an individual's writing. Some may argue that this black-boxing reflects rubric grading or a writing instructor's unwritten grading criteria. But the difference that remains is a dialogue can be had with an instructor to engage in this socially embedded practice of writing. Instead, with AWE, the writer is pressured to accept the assessment, while the programmers are able to conceal themselves behind a digital wall of unknown codes being enacted by an untalkative system of rules. This situation forces the writer to not only understand the writing they are doing, but why the AWE assessed them the way it did. How often have we sat next to a person (or been the person ourselves) playing a digital game and yelling when the software glitched or disrupted the player unexpectedly? The same frustration, we believe, exists when an AWE provides an unexplained, unwanted assessment towards a writer.
The companies of these AWE would likely defend themselves behind proprietary reasons for why they keep their algorithms occluded to the public. But in doing so, they create technical illiteracy not just of their algorithm but of the output of that algorithm. These systems are asking the writer to blindly trust and treat these programs as the purveyors of writing knowledge. While completely "unboxing" the algorithm may not be a realistic possibility in the near future, the AWE at the very least should be forthcoming about what guiding research of writing assessment was used to build the algorithm and the types of data informing the system's feedback. Christian (2020) aptly recognizes the potential danger when we do not know who or what is represented in the training data for algorithms to perform their functions. And when the history of writing is so vast, obviously the programmers are making choices for what they find useful for the AWE. That is if they are considering the history of writing at all, as compared to programming based on their own writing education. Knowing or understanding those choices would be beneficial for the writer to understand what a particular AWE can provide. This knowledge would not just be in what the AWE advertises, but rooted in knowing the true capabilities and effectiveness of the algorithm's assessment. This is more important when the social engagement of the writing process is moved from human to computer. But this was preliminary research to contribute to conversations on AWE's functions in writing assessment. These programs are often looked at as being beneficial for their utility to help with labor management or instant accessibility. Feedback and assessment however, are an integral part of the writing process, and it would be remiss to ignore or to not intricately critique its shortcomings, especially when these programs are being used in other subject fields beyond English.
These conversations must also be understood in connection with those around large language models (LLM), such as GPT-3 and ChatGPT, which would also help us to understand how writing is conducted in online environments beyond assessment. Similar concerns remain: what writing styles are valued by these models? With LLMs algorithmic black-boxing is still a major issue because we do not explicitly know what data is informing the system and what writing histories played a role in shaping the output by the algorithm, even if some of these systems provide general information on their data source such as OpenAI's scrapping of the internet.
Inevitably, these programs are becoming increasingly prevalent in everyday life. Think of how many people are now using Grammarly in academic and other contexts. Given that prevalence, we can not simply accept AWE as they are or trust that they function as they claim. We must take the time to truly unpack and understand these algorithms or at the very least the information that informs them. What standards and norms of writing are we enforcing? Who might those standards exclude and will they reinforce harmful power structures which devalue a student's language? And, how do these AWE capture or reject students' individual writing styles and choices? To know, we need to unpack the black-box.
References
Berlin, James A. (1980). Richard Whately and current-traditional rhetoric. College English, 42(1), 10–17. doi:10.2307/376028
Brock, Kevin. (2019). Rhetorical code studies: Discovering arguments in and around code. University of Michigan Press.
Brock, Kevin & Shepherd, Dawn. (2016). Understanding how algorithms work persuasively through the procedural enthymeme. Computers and Composition, 42, 17–27. doi:10.1016/j.compcom.2016.08.007
Burrell, Jenna. (2016). How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data & Society, 3(1), 1–12. doi:10.1177/2053951715622512
Charlton, Colin. (2014). The weight of curious space: Rhetorical events, hackerspace, and emergent multimodal assessment. Computers and Composition, 31, 29–42. doi:10.1016/j.compcom.2013.12.002
Christian, Brian. (2020). The alignment problem: Machine learning and human values. W. W. Norton & Company.
Conference on College Composition and Communication. (1974). Students' right to their own language. College Composition and Communication, 25(3), 1–32.
Connors, Robert J. (1997). Composition-rhetoric: Backgrounds, theory, and pedagogy. University of Pittsburgh Press. doi:10.2307/j.ctt5hjt92
Ericsson, Patricia Freitag, & Haswell, Richard H. (Eds.). (2006). Machine scoring of student essays: Truth and consequences. Utah State University Press.
Ernst, Daniel. (2020). The android English teacher: Writing education in the age of automation (Publication No. 30503616). [Doctoral dissertation, Purdue University] ProQuest Dissertations & Theses Global. https://www.proquest.com/dissertations-theses/android-english-teacher-writing-education-age/docview/2827706680/se-2
Francher, Patricia. (2021). A feeling for the algorithm: A feminist methodology for algorithmic writing and research. Journal of Multimodal Rhetorics, 5(2), 27–44.
Gallagher, John R. (2020). The ethics of writing for algorithmic audiences. Computers and Composition 57(4), 102583.
Gallagher, John R. (2023). Lessons learned From machine learning researchers about the terms “Artificial Intelligence” and “Machine Learning.” Composition Studies 51(1), 149–154.
Haswell, Richard H. (2006). Automatons and automated scoring: Drudges, black boxes, and dei ex machina. In P. F. Ericsson & R. Haswell (Eds.), Machine scoring of student essays: truth and consequences (pp. 57–78). Utah State University Press.
Herrington, Anne, & Moran, Charles. (2001). What happens when machines read our students’ writing? College English, 63(4), 480–499. http://www.jstor.com/stable/378891
Hirst, Russel. (2003). Scientific jargon, good and bad. Journal of Technical Writing and Communication, 33(3), 201–229.
Hockly, Nicky. (2019). Automated writing evaluation. ELT Journal 73(1), 82–88.
Huang, Yue, & Wilson, Joshua. (2021). Using automated feedback to develop writing proficiency. Computers and Composition 62(4), 102675.
Johnson, Jeremy David. (2020). Theorizing network bias and teaching mêtic invention in online search. Computers and Composition 56(3), 102573.
Laflen, Angela. (2023). Exploring how response technologies shape instructor feedback: A comparison of Canvas Speedgrader, Google Docs, and Turnitin GradeMark. Computers and Composition 68(3), 102777.
Laio, Hui-Chuan. (2016). Using automated writing evaluation to reduce grammar errors in writing. ELT Journal 40(3), 308–319. doi:10.1093/elt/ccv058
Latour, Bruno. (1987). Science in action. Harvard University Press.
Latour, Bruno. (1999). Pandora’s hope: Essays on the reality of science studies. Harvard University Press.
Lee, Young-Ju. (2020). The long-term effect of automated writing evaluation feedback on writing development. English Teaching 75(1), 67–92. doi:10.15858/engtea.75.1.202003.67
Moura, Ian. (2023). Encoding Normative Ethics: On Algorithmic Bias and Disability. First Monday 28(1). https://doi.org/10.5210/fm.v28i1.12905
O’Neill, Ruth, & Russell, Alex M. T. (2019). Stop! Grammar time: University students’ perceptions of the automated feedback program Grammarly. Australasian Journal of Educational Technology 35(1), 42–56.
Pengilly, Cynthia. (2021). Confronting Ableist Texts: Teaching Usability and Accessibility in the Online Technical writing Classroom. In J. Borgman & C. McArdle (Eds.), PARS in Practice: More Resources and Strategies for Online Writing Instructors (pp. 153–166). The WAC Clearinghouse; University Press of Colorado. https://doi.org/10.37514/PRA-B.2021.1145.2.09
ProWritingAid. About us. Retrieved January 3, 2023, from https://prowritingaid.com/en/Home/AboutUs
ProWritingAid. Pacing. Retrieved January 1, 2023, from https://prowritingaid.com//grammar/1008122/Pacing
Shaheen, Natalie L. (2021). Accessibility4Equity: Cripping Technology-Mediated Compulsory Education Through Sociotechnical Praxis. British Journal of Educational Technology 53(9), 77–92. https://doi.org/10.1111/bjet.13153
Shew, Ashley. (2020). Ableism, Technoableism, and Future AI. IEEE Technology and Society Magazine 39(1), 40–85. https://doi.org/10.1109/MTS.2020.2967492
Wilson, Joshua, Ahrendt, Cristina, Fudge, Emily A., Raiche, Alexandria, Beard, Gaysha, & MacArthur, Charles. (2021). Elementary teachers’ perceptions of automated feedback and automated scoring: Transforming the teaching and learning of writing using automated writing evaluation. Computers & Education, 168, 1–11. doi:10.1016/j.compedu.2021.104208
Wilson, Joshua, & Roscoe, Rod D. (2020). Automated writing evaluation and feedback: Multiple metrics of efficacy. Journal of Educational Computing Research, 58(1), 87–125. doi:10.1177/0735633119830764
1Alexis allowed us to use her data for this chapter but decided not to proceed as a co-author.